a simple, non-fragile solution for configuring vim and similar programs
around the n-th time i got a new laptop and had to manually set up my vim, i realized that i was probably doing something wrong
so, like professor muratorio before me, i wrote the usage code first
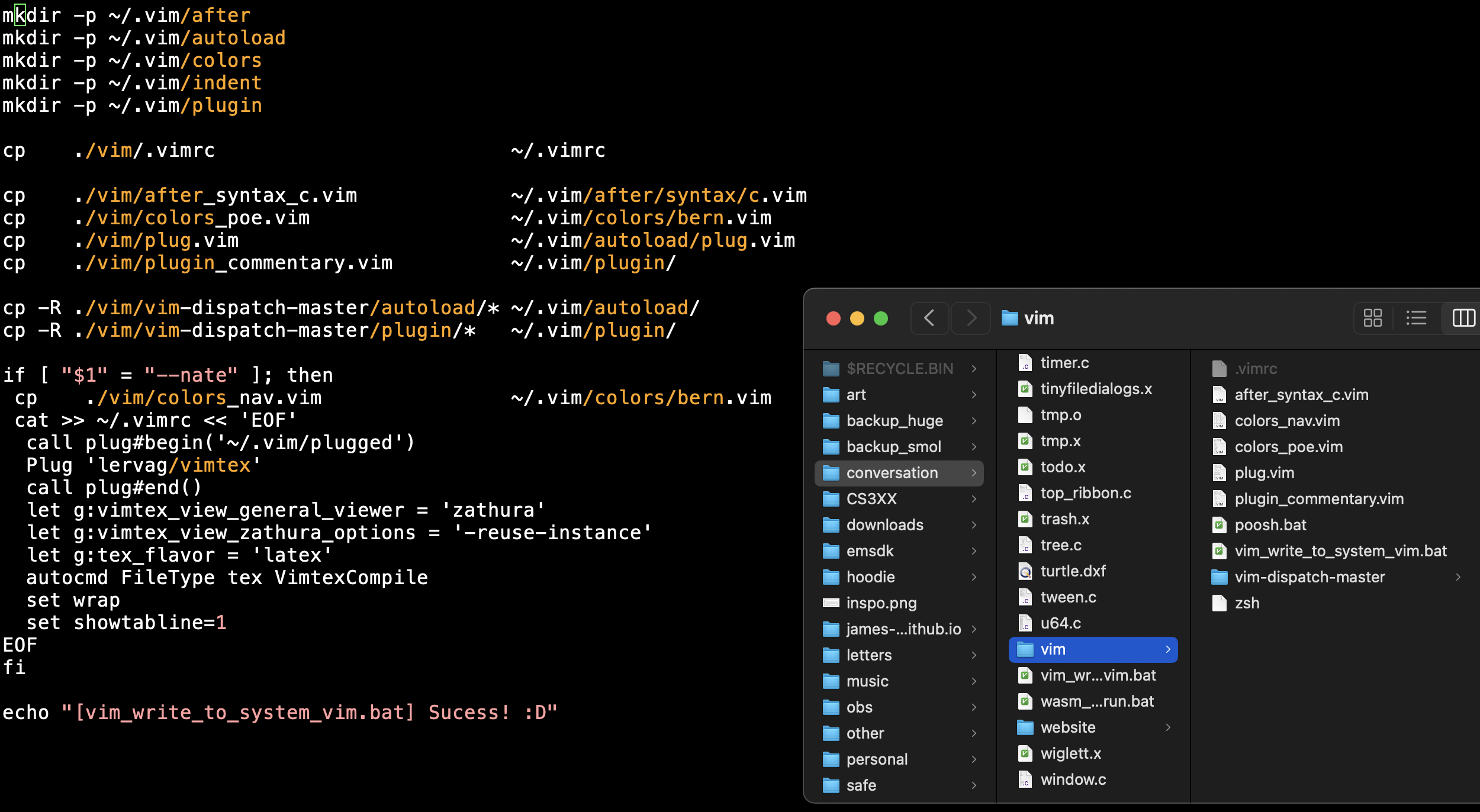
THE USAGE CODE (what i really want, in my heart of hearts): want to just run a single script called vim_setup.sh or whatever, and have it set up my vim (like a build_and_run.bat, but for setting up vim) so that i don't have to remind myself how vim's directory structure works or where i found that one plugin or AHHHHHHHH
this script and all its dependencies should live in my github repo, so that when i get a new computer i can just 1) clone the repo, 2) run the script, and 3) get back to coding
while this script might sound like some very magical, complicated thing that needs to curl and git submodule and pathogen infect VimPlug puppet ???, this is incorrect
the reason it's incorrect is that on my laptop, "configure vim" literally just means "set the contents of the file ~/.vimrc and the folder ~/.vim/"
that's it.
period.
the end.
so, if my git repo contains my desired .vimrc and .vim/
(like, contains the literal contents of that file and that folder. NOT contains some other script or submodule hook or recipe or AHHHHHHH...
...but no, i really mean the repo has .vimrc and .vim/ and that file and that folder contain THE LITERAL CODE that vim will actually read)
then all vim_setup.sh needs to do is copy them into my computer's home directory
hilariously (if you find this kind of thing funny), this extends immediately to multiple profiles
i often partner code with one of my students, who has his own vim setup (basically mine, but with different colors, plus the ability to read pdf's or something)
and both of our setups live in our shared repo, along with our own vim_setup.sh's (technically, i think his is mine with a command-line argument, but the principle is the same)
to make switching back and forth really easy, we can just add remap <leader>P to run my setup script and <leader>N to run his
sidenote: i don't know what problem pathogen or VimPlug are supposed to be solving. when i find a vim plugin i want, i just manually copy its files into my repo's copy of .vim/; i have no interest in updating any of my plugins ever
i've tried a lot of ways of keeping track of my TODO's and so far only one has even sort of worked
first, here's some approaches that didn't work for me
a) scattering the TODO's throughout the code -- they accumulate and become meaningless and overwhelming; plus they distract from explanatory comments
b) curating the TODO's in GitHub issues -- way too much friction; requires me to be connected to the internet; end up piling up and becoming meaningless
c) no TODO list (follow your heart 🥺) -- unfortunately, my heart is a dumb dumb (boring ideas never gets done, fun/stupid ideas always get started but rarely get finished)
and here's an approach that did work for me
- i have one file called todo.x and another file called done.x
- if i have an idea for something to do, i add it to todo.x, for example...
// TODO make a less exciting test_eso that doesn't require transforms, etc. (just draw the primitives yo)
- if i end up doing it, i replace TODO with DONE and move it to done.x
that's pretty much it, just a big 'ol list 🤷
one last thing: since marking the TODO as done and moving it over by hand is frictious, i wrote a Vim mapping that marks the TODO as DONE and moves it over to done.txt also also pushes to github the body of the TODO as the commit message
the only downside i experienced using these String's was that the standard printf didn't know about them -- if you pass a non-null terminated one of these String's with %s, printf will just goes marching merrily off into the distance, looking for a 0 that may never come
i saw two ways around this (like always, there are probably more options than just these):
A) remember to add null-terminators whenever i wanted to print of sprint, or
B) bring your own printf
conventional wisdom has that option (B) is Bad and Hard, but conventional wisdom is basically always wrong, so let's go with option (B)
case 'S' : { // our custom String struct
String string = va_arg(va, String);
const char *p = string._;
unsigned int l = (unsigned int) string.length;
if (l) {
// NOTE this block (mostly) copy and pasted from case 's' i did need to
// change / add one important thing or else it did bad things beware copypasta
...
}
}
sidenote: while i was in the neighborhood, i made a small change to _internal_vsnprintf(...) -- i prefer my functions to just crash the program when they fail, rather than returning some number i'll forget to check for and then spend hours trying to debug the downstream effects of
int _internal_vsnprintf(...) {
...
// // NOTE (copied from the printf docs)
// \return The number of characters that COULD have been written into the buffer, not counting the terminating
// null character. A value equal or larger than count indicates truncation. Only when the returned value
// is non-negative and less than count, the result has been completely written.
B32 success = (1
&& (result >= 0)
&& ((size_t) result < maxlen)
);
if (!success) {
*((volatile S32 *) 0) = 0; // (crash)
}
return(result);
}
i like being able to easily delete lines and swap lines without having to think about C's syntax;
one useful family of tricks is to avoid syntactic "special cases" -- basically, the first and last of something should be styled just like the things in the middle
here's how i initialize structs
{
a,
b,
c, // <- i put a comma here (NOTE trailing comma in struct-initialization is valid C)
}
here's how i write an else-if ladder
if (0) { // <- i put an `if (0)` here (NOTE 0 is false)
} else if (...) {
...
} else if (...) {
...
} else if (...) {
...
}
here's how i write an AND chain
(1 // <- i put a `1` here (NOTE 1 is true)
&& ...
&& ...
&& ...
)
here's an example snippet from Conversation's source